










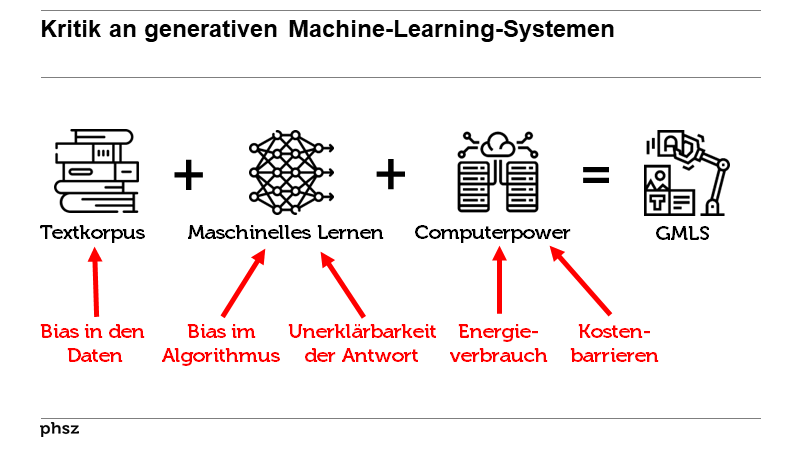
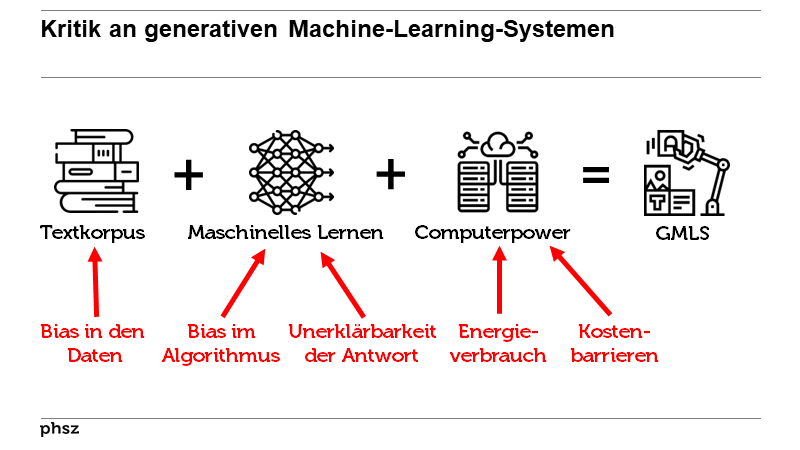
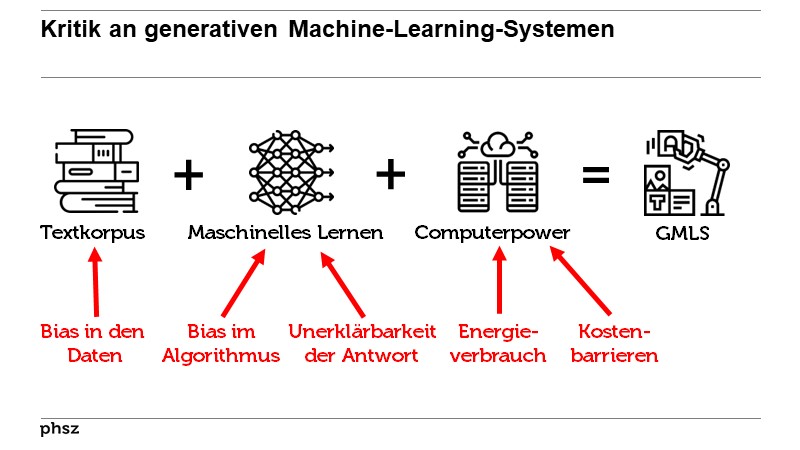
Machine Learning kann bestehende Vorurteile/Ungerechtigkeiten verstärken/weitertragen
 BiblioMap
BiblioMap 
 Definitionen
Definitionen
 Machine learning algorithms, for example, are trained on real-life data and so tend to reflect the biases of society.
Machine learning algorithms, for example, are trained on real-life data and so tend to reflect the biases of society.But studies indicate that in some current contexts, the downsides of AI systems disproportionately affect groups that
are already disadvantaged by factors such
as race, gender and socio-economic background.
Von Kate Crawford, Ryan Calo im Text There is a blind spot in AI research (2016)  Bemerkungen
Bemerkungen
 Noch neigen Textgeneratoren zum
Verstärken von Vorurteilen und Klischees.
Noch neigen Textgeneratoren zum
Verstärken von Vorurteilen und Klischees. Wo vorher (gerechtfertigt oder ungerecht- fertigt) diskriminiert wurde, wird die Maschine diese Diskriminierung mitlernen.
Wo vorher (gerechtfertigt oder ungerecht- fertigt) diskriminiert wurde, wird die Maschine diese Diskriminierung mitlernen.Aufgrund von statistischen
Verzerrungen oder ungenügenden Modellen können etwa einzelne Personen oder Personengruppen
diskriminiert werden.
Von Christian R. Ulbrich, Urs Gasser im Text Die wahren Kosten der Künstlichen Intelligenz (2024) In a 2013 study, for example, Google
searches of first names commonly used by
black people were 25% more likely to flag
up advertisements for a criminal-records
search than those of ‘white-identifying’
names.
Von Kate Crawford, Ryan Calo im Text There is a blind spot in AI research (2016)  When we train machines to make decisions based on data that arise in a biased society, the machines learn and perpetuate those same biases. In situations like this, “machine learning” might better be called “machine indoctrination.”
When we train machines to make decisions based on data that arise in a biased society, the machines learn and perpetuate those same biases. In situations like this, “machine learning” might better be called “machine indoctrination.”die heutigen KI-Systeme sind bereits schädigend. Sie reproduzieren Stereotype, sie haben einen rassistischen und sexistischen Bias, weil sie ja mit Texten, Bildern und Videos aus dem gesamten Internet trainiert und gefüttert werden.
Von Meredith Whittaker im Text «Wer dem KI-Hype verfällt, stärkt die Macht der Big-Tech-Chefs» (2023)  Einige Untersuchungen legen nahe,
dass maschinell trainierte Systeme Stereotype
sogar verstärken: So tendierte eine
KI für Szenenerkennung dazu, in der
Küche befindliche Personen als Frau zu
taggen, auch wenn sie männlich waren.
Einige Untersuchungen legen nahe,
dass maschinell trainierte Systeme Stereotype
sogar verstärken: So tendierte eine
KI für Szenenerkennung dazu, in der
Küche befindliche Personen als Frau zu
taggen, auch wenn sie männlich waren.In summary, LMs trained on large, uncurated, static datasets from
the Web encode hegemonic views that are harmful to marginalized
populations. We thus emphasize the need to invest significant resources
into curating and documenting LM training data.
Von Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell im Text On the Dangers of Stochastic Parrots (2021) In another race-related finding, a
ProPublica investigation in May 2016 found
that the proprietary algorithms widely used
by judges to help determine the risk of reoffending are almost twice as likely to mistakenly flag black defendants than white
defendants
Von Kate Crawford, Ryan Calo im Text There is a blind spot in AI research (2016) Bei wichtigen Algorithmen müsste bewiesen werden, dass sie fair sind, statistisch aussagekräftig und dass es eine Feedbackschleife gibt, die prüft, ob sie funktionieren. Dass sie weder sexistisch noch rassistisch sind. Dass niemand benachteiligt wird. Und wenn es ein Problem gibt, muss der Algorithmus optimiert werden.
Von Cathy O'Neil im Text «Algorithmen entscheiden, ob wir Gewinner oder Verlierer sind» (2017) Forscher befürchten
deshalb, dass mühsam errungene gesellschaftliche
Fortschritte – etwa die Chancengleichheit
von Menschen unabhängig
von Geschlecht und Herkunft – unterminiert
werden könnten, wenn die vermeintlich
neutralen maschinellen Entscheider
immer mehr Bereiche des gesellschaftlichen
Lebens mitgestalten. Diese
Modelle haben eindeutig das Potenzial, ebenso giftig wie mächtig zu sein.
Da sie großteils mit den im offenen Web verfügbaren chaotischen Daten
trainiert sind, werden sie quasi en passant die zugrunde liegenden Vorurteile
und Strukturen der Gesellschaft reproduzieren und sogar verstärken,
sofern sie nicht so sorgfältig konzipiert sind, dass sie das vermeiden.
Diese
Modelle haben eindeutig das Potenzial, ebenso giftig wie mächtig zu sein.
Da sie großteils mit den im offenen Web verfügbaren chaotischen Daten
trainiert sind, werden sie quasi en passant die zugrunde liegenden Vorurteile
und Strukturen der Gesellschaft reproduzieren und sogar verstärken,
sofern sie nicht so sorgfältig konzipiert sind, dass sie das vermeiden.Bei selbstlernenden Systemen ist schwer nachzuvollziehen, ob ihre Entscheidungen auch unseren Erwartungen entsprechen. Das Feld der KI-Ethik diskutiert diese Gefahr unter dem Begriff des bias – Verzerrungen, die bestehende Ungerechtigkeit wiederholen oder gar verstärken. So können KI-Systeme nicht nur den Rassismus oder den Sexismus widerspiegeln, den sie aus den Daten der Welt gelernt haben, sondern ihn auch noch potenzieren und so selbst aktiv Ungerechtigkeit hervorbringen.
Von Hannes Bajohr im Text Wer sind wir? Warum künstliche Intelligenz immer ideologisch ist (2021) Das Potenzial für Schaden, Missbrauch und Desinformation ist real.
Die gute Nachricht ist jedoch, dass viele dieser Probleme mit größeren
und leistungsfähigeren Modellen verbessert werden können. Forscher auf
der ganzen Welt arbeiten eifrig an der Entwicklung einer Reihe von neuen
Feinabstimmungs- und Kontrolltechniken, die bereits einen Unterschied
machen und ein Maß an Robustheit und Zuverlässigkeit bieten, das noch
vor wenigen Jahren unmöglich war. Natürlich ist noch viel mehr nötig,
aber zumindest wird dieses schädliche Potenzial jetzt mit Nachdruck bekämpft. In educational data and administrative systems, past data used to make predictions and interventions about present students can amplify historical forms of bias and discrimination. Problems of bias and discrimination in AI in general could lead to life-changing consequences in a sector like education. Moreover, racial and gender stereotypes are a widespread problem in generative AI applications; some generative AI applications produced by right wing groups can also generate overtly racist content and disinformation narratives, raising the risk of young people accessing political propaganda.
Von Ben Williamson im Text AI in education is a public problem (2024) Starting with who is contributing to these Internet text collections,
we see that Internet access itself is not evenly distributed,
resulting in Internet data overrepresenting younger users and those
from developed countries [100, 143].12 However, it’s not just the Internet
as a whole that is in question, but rather specific subsamples
of it. For instance, GPT-2’s training data is sourced by scraping outbound
links from Reddit, and Pew Internet Research’s 2016 survey
reveals 67% of Reddit users in the United States are men, and 64%
between ages 18 and 29.13 Similarly, recent surveys of Wikipedians
find that only 8.8–15% are women or girls [9].
Von Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell im Text On the Dangers of Stochastic Parrots (2021) Es gibt auch wichtige Beobachtungen zur DatenauswahL Erstens sind beim Titanic-D&tenset wie in vielen anderen Fällen auch die Daten nicht vollständig und teilweise vielleicht falsch. Zweitens steckt eine Diskriminierung in den Daten: Frauen und Kinder wur- den bei der Besetzung der Rettungsboote bevorzugt. Würde man also den entstandenen Baum nutzen, um für das nächste Unglück Entscheidungen zu treffen, wen man rettet, würden diese Diskriminierungen verstärkt! Wenn der Entscheidungsbaum jeweils nach der Mehrheit in den Blättern entscheidet, kämen sogar nur noch Frauen, Mädchen und kleine Jungs in die Boote. Eine Datenbasis mit einer Diskrüninierung schreibt diese also fort und kann sie so- gar noch verstärken - je nachdem, wie das gefundene statistische Modell genutzt wird. Die Anwendung von LLMs ist also
unter dem Vorbehalt zu betrachten,
dass dadurch strukturelle Ungerechtigkeiten
verfestigt werden. Die Nutzung
von LLM-gestützten Systemen in sämtlichen
Bereichen – beispielsweise in
Wissenschaft und Forschung, dem öffentlichen
Sektor zur Rechts- oder Sozialberatung
oder im Gesundheitswesen
– birgt die Gefahr, strukturelle Ungerechtigkeiten
zu verstetigen. Marginalisierte
Gruppen sowie in aktuellen Aushandlungsprozessen
kaum sichtbare
Gruppen wie zum Beispiel People of
Color, Menschen mit geringem sozioökonomischem
Status, unterschiedlichen
Geschlechtsidentitäten oder verschiedenen
sexuellen Orientierungen
bleiben unsichtbar. Sie sind in den Daten
unterrepräsentiert und in der Mustererkennung
von LLMs und Entscheidungsunterstützungssystemen
nicht hinreichend
repräsentiert.
Die Anwendung von LLMs ist also
unter dem Vorbehalt zu betrachten,
dass dadurch strukturelle Ungerechtigkeiten
verfestigt werden. Die Nutzung
von LLM-gestützten Systemen in sämtlichen
Bereichen – beispielsweise in
Wissenschaft und Forschung, dem öffentlichen
Sektor zur Rechts- oder Sozialberatung
oder im Gesundheitswesen
– birgt die Gefahr, strukturelle Ungerechtigkeiten
zu verstetigen. Marginalisierte
Gruppen sowie in aktuellen Aushandlungsprozessen
kaum sichtbare
Gruppen wie zum Beispiel People of
Color, Menschen mit geringem sozioökonomischem
Status, unterschiedlichen
Geschlechtsidentitäten oder verschiedenen
sexuellen Orientierungen
bleiben unsichtbar. Sie sind in den Daten
unterrepräsentiert und in der Mustererkennung
von LLMs und Entscheidungsunterstützungssystemen
nicht hinreichend
repräsentiert.Inzwischen weiss man: So einfach ist es nicht mit dem Ausmerzen von Vorurteilen und Stereotypen. Das zeigt etwa der Fall Amazon, der vor wenigen Wochen Schlagzeilen machte. Der Onlineversandhändler musste ein Rekrutierungsprojekt stoppen, weil dieses Frauen benachteiligte – wenn auch unabsichtlich. Für das Projekt hatte Amazon ein Computerprogramm entwickelt. Dieses sollte aus Hunderten eingehender Bewerbungen die besten auswählen, indem es die Bewerbungen nach Schlüsselbegriffen prüfte, welche für die jeweilige Stelle entscheidend waren. Gefüttert und trainiert wurde die Software mit erfolgreichen Bewerbungen von bereits angestellten Mitarbeitenden. Nun ist aber die Belegschaft bei Amazon – wie in der Technologiebranche üblich – hauptsächlich männlich. Das selbst lernende Programm erkannte dies und folgerte, dass Männer besser geeignet seien. So kam es, dass Bewerbungen von Frauen eher herausgefiltert wurden.
Von Andrea Fischer im Text Auch Maschinen können benachteiligen (2018) auf Seite 11 Any fears we might have about unfair automated job rejection were illustrated in Amazon’s development of job-hiring software, which relied on algorithms trained on a data set of thousands of resumes that the company had used in their previous job hire decisions. By mathematically modeling the ideal types of applicants that the company had hired previously through human interview panels, the algorithm was faithfully reproducing the (un)conscious bias in decision-making that disproportionately favored male engineers. As was reported at the time, Amazon’s system taught itself that male candidates were preferable and eliminated or penalized résumés that included the word “women”—for example, as might be detected in the phrase “women’s chess club captain” (Dastin 2018). To paraphrase an old computer science adage, this was a case of “prejudice in, prejudice out.” This is a clear instance of the “coded bias” that Joy Buolamwini and colleagues were warning us about.Aus Bewerbungsunterlagen und anderen
Textdokumenten lassen sich Geschlecht
und Name einfach löschen. Das Ergebnis
sind scheinbar neutrale Trainingsdaten,
die weder Frauen noch Menschen mit
Migrationshintergrund benachteiligen.
Doch manches Datenmaterial ist einfach
derart durchtränkt von verräterischen
Merkmalen wie Wohngegend, Besuch
einer reinen Mädchen-/Jungenschule et
cetera – , dass sich die Datensätze nicht
vernünftig neutralisieren lassen, ohne sie
komplett zu entwerten.
Any fears we might have about unfair automated job rejection were illustrated in Amazon’s development of job-hiring software, which relied on algorithms trained on a data set of thousands of resumes that the company had used in their previous job hire decisions. By mathematically modeling the ideal types of applicants that the company had hired previously through human interview panels, the algorithm was faithfully reproducing the (un)conscious bias in decision-making that disproportionately favored male engineers. As was reported at the time, Amazon’s system taught itself that male candidates were preferable and eliminated or penalized résumés that included the word “women”—for example, as might be detected in the phrase “women’s chess club captain” (Dastin 2018). To paraphrase an old computer science adage, this was a case of “prejudice in, prejudice out.” This is a clear instance of the “coded bias” that Joy Buolamwini and colleagues were warning us about.Aus Bewerbungsunterlagen und anderen
Textdokumenten lassen sich Geschlecht
und Name einfach löschen. Das Ergebnis
sind scheinbar neutrale Trainingsdaten,
die weder Frauen noch Menschen mit
Migrationshintergrund benachteiligen.
Doch manches Datenmaterial ist einfach
derart durchtränkt von verräterischen
Merkmalen wie Wohngegend, Besuch
einer reinen Mädchen-/Jungenschule et
cetera – , dass sich die Datensätze nicht
vernünftig neutralisieren lassen, ohne sie
komplett zu entwerten.Genau aus diesem Grund hat Amazon eine intern entwickelte KI zur Bewerberauswahl wieder eingestampft. Sie wurde mit den Unterlagen von Personen trainiert, die sich in der Vergangenheit erfolgreich bei Amazon beworben hatten. Das Ziel: aus einer Masse an Bewerbern automatisch die fünf geeignetsten Kandidaten herauszufiltern. Doch der Algorithmus bevorzugte nicht nur systematisch Männer, sondern schlug auch gänzlich unqualifizierte Kandidaten vor. Offensichtlich hatte die KI, die mit überwiegend männlich geprägten Bewerbungsunterlagen trainiert wurde, Indizien für einen männlichen Bewerber so stark gewichtet, dass dabei sogar die fachliche Qualifikation unter den Tisch fiel. Frappierend ist auch hier, dass sich die Daten offensichtlich nicht vernünftig aufbereiten ließen.
Laut Amazon hat die Empfehlung der KI niemals die Entscheidung für oder gegen einen Bewerber beeinflusst.
 8 Vorträge von Beat mit Bezug
8 Vorträge von Beat mit Bezug
- BBZGPT
Berufsbildungszentrum Goldau, 17.08.2023

- Nachrichtenkompetenz – und jetzt auch noch ChatGPT & Co.
Tagung "Nachrichtenkompetenz auf Sekundarstufe II" von ZHAW und SRG public value, 03.11.2023
- Wenn ChatGPT in der Lehrer:innenbildung mitredet
(Video des Referats)
Tag der Lehre der PHZH, 01.02.2024
- Was will uns ChatGPT sagen?
8. Pädagogischer Dialog Liechtenstein, Vaduz, 21.02.2024
- Sprachmaschinen.
Deutschsprachige AG Fremdsprachen der EDK, PHZH, 20.03.2024
- Überfluten uns ChatGPT & Co.?
Tagung des Berufsverbands Schulleitungen Bern
Schwellenmätteli Bern, 24.05.2024
- Generative Machine-Learning-Systeme in der Bildung
VR- und GL-Retraite der Orell Füssli Gruppe
Hasliberg, 12.06.2024
- Wenn das Digitale in der Bildung mitzureden beginnt
Bildungstag Kanton Glarus, 04.09.2024
 Zitationsgraph
Zitationsgraph
Zitationsgraph (Beta-Test mit vis.js)
 Zeitleiste
Zeitleiste
 72 Erwähnungen
72 Erwähnungen
- Quantifying ChatGPT’s gender bias (Sayash Kapoor, Arvind Narayanan)

- Weapons of Math Destruction - How Big Data Increases Inequality and Threatens Democracy (Cathy O’Neil) (2016)

- The AI Now Report - The Social and Economic Implications of Artificial Intelligence Technologies in the Near-Term (Kate Crawford, Meredith Whittaker) (2016)
- There is a blind spot in AI research (Kate Crawford, Ryan Calo) (2016)
- Technically Wrong - Sexist Apps, Biased Algorithms, and Other Threats of Toxic Tech (Sara Wachter-Boettcher) (2017)
- «Algorithmen entscheiden, ob wir Gewinner oder Verlierer sind» (Cathy O'Neil, Corinna Daus) (2017)
- Automating Inequality (Virginia Eubanks) (2018)
- Wo Maschinen irren können - Verantwortlichkeiten und Fehlerquellen in Prozessen algorithmischer Entscheidungsfindung (Katharina A. Zweig, Sarah Fischer, Konrad Lischka) (2018)
- Neuronale Denkfehler - Künstliche Intelligenz: zu naiv, um schlau zu sein (Schwerpunktthema c't 24/18) (2018)
- Irren ist künstlich - Wo künstliche Intelligenz noch schwächelt (Andrea Trinkwalder)
- Irren ist künstlich - Wo künstliche Intelligenz noch schwächelt (Andrea Trinkwalder)
- Auch Maschinen können benachteiligen (Andrea Fischer) (2018)
- Diskriminierungsrisiken durch Verwendung von Algorithmen - Eine Studie, erstellt mit einer Zuwendung der Antidiskriminierungsstelle des Bundes. (Carsten Orwat) (2019)
- Ein Algorithmus hat kein Taktgefühl - Wo künstliche Intelligenz sich irrt, warum uns das betrifft und was wir dagegen tun können (Katharina A. Zweig) (2019)
- Calling Bullshit - The Art of Skepticism in a Data-Driven World (Carl T. Bergstrom, Jevin D. West) (2020)
- The Alignment Problem (Brian Christian) (2020)
- Data Feminism (Catherine D'Ignazio, Lauren F. Klein) (2020)
- 1. The Power Chapter - Principle: Examine Power
- 1. The Power Chapter - Principle: Examine Power
- Vor dem Algorithmus sind nicht alle gleich (Michael Moorstedt) (2020)
- On the Dangers of Stochastic Parrots - Can Language Models Be Too Big? (Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell) (2021)
- Image Representations Learned With Unsupervised Pre-Training Contain Human-like Biases (Ryan Steed, Aylin Caliskan) (2021)
- Die Informatik ist männlich - Wie Frauen aus der digitalen Welt verdrängt wurden - und warum sie ihren Platz zurückerobern müssen (Nadine A. Brügger) (2021)
- Wer sind wir? Warum künstliche Intelligenz immer ideologisch ist (Hannes Bajohr) (2021)
- «Plötzlich gehörten für Computer ‹Mexikaner› und ‹illegal› zusammen» (Doris Allhutter, Karin Cerny) (2021)
- Klick - Wie wir in einer digitalen Welt die Kontrolle behalten und die richtigen Entscheidungen treffen (Gerd Gigerenzer) (2021)
- Digital Warriors (Roberta Fischli) (2022)
- 1. Humane Algorithmen - dafür legt sie sich mit Amazon an (2022)
- 1. Humane Algorithmen - dafür legt sie sich mit Amazon an (2022)
- Beyond Measure - The Hidden History of Measurement (James Vincent) (2022)
- 10. The Managed Life
- Lemoine und die Maschine – eine Beziehungsgeschichte (Eva Wolfangel) (2022)
- What do NLP researchers believe? (Julian Michael, Ari Holtzman, Alicia Parrish, Aaron Mueller, Alex Wang, Angelica Chen, Divyam Madaan, Nikita Nangia, Richard Yuanzhe Pang, Jason Phang, Samuel R. Bowman) (2022)
- Das sprachgewaltige Plappermaul (Eva Wolfangel) (2022)
- Against automated plagiarism (Iris van Rooij) (2022)
- Do not feed the Google - Republik-Serie (2023)
- 4. Wenn ethische Werte nur ein Feigenblatt sind (Daniel Ryser, Ramona Sprenger) (2023)
- 4. Wenn ethische Werte nur ein Feigenblatt sind (Daniel Ryser, Ramona Sprenger) (2023)
- «Ein Chatbot kann nicht logisch denken» (Emily M. Bender, Ruth Fulterer) (2023)
- You Are Not a Parrot (Elizabeth Weil) (2023)
- Die neue Weltmacht - Wie ChatGPT und Co. unser Leben verändern (Titelthema Spiegel 10/2023) (2023)
- Wie Maschinen träumen lernen (Carola Padtberg, Tobias Rapp)
- Wie Maschinen träumen lernen (Carola Padtberg, Tobias Rapp)
- KI-Expertin: «Krasse Reduktion der Realität» (Cornelia Diethelm, Tina Fischer) (2023)
- The A.I. Dilemma (Tristan Harris, Aza Raskin) (2023)
- Ein Schawinski, der künstlicher Intelligenz Nachhilfe gibt (Simone Luchetta) (2023)
- Forschung und Lehre 4/23 (2023)
- Wissen und nicht wissen - ChatGPT & Co. und die Reproduktion sozialer Anerkennung (Hannah Bleher, Matthias Braun) (2023)
- Wissen und nicht wissen - ChatGPT & Co. und die Reproduktion sozialer Anerkennung (Hannah Bleher, Matthias Braun) (2023)
- Wie nah sind wir an der Superintelligenz? (Eva Wolfangel) (2023)
- Sparks of Artificial General Intelligence - Early experiments with GPT-4 (Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang) (2023)
- ChatGPT und andere Computermodelle zur Sprachverarbeitung - Grundlagen, Anwendungspotenziale und mögliche Auswirkungen (Steffen Albrecht) (2023)
- Speak, Memory - An Archaeology of Books Known to ChatGPT/GPT-4 (Kent K. Chang, Mackenzie Cramer, Sandeep Soni, David Bamman) (2023)
- Chat GPTs als eine Kulturtechnik betrachtet - eine philosophische Reflexion (Sybille Krämer) (2023)
- Was hinter der lauten Warnung vor der KI-Apokalypse steckt (Jannis Brühl) (2023)
- Zehn Thesen zur Zukunft des Schreibens in der Wissenschaft (Anika Limburg, Ulrike Bohle-Jurok, Isabella Buck, Ella Grieshammer, Johanna Gröpler, Dagmar Knorr, Margret Mundorf, Kirsten Schindler, Nicolaus Wilder) (2023)
- Sollen Frauen Karriere machen? (Joachim Laukenmann) (2023)
- The Coming Wave - Technology, Power, and the Twenty-first Century's Greatest Dilemma (Mustafa Suleyman, Michael Bhaskar) (2023)
- Apokalypse als Businessmodell (Felix Maschewski, Anna-Verena Nosthoff) (2023)
- Unmasking AI (Joy Buolamwini) (2023)
- c't KI-Praxis (2023)
- Systemsprenger (Andrea Trinkwalder) (2023)
- Systemsprenger (Andrea Trinkwalder) (2023)
- Critical Data Literacies - Rethinking Data and Everyday Life (Luci Pangrazio, Neil Selwyn) (2023)
- Datafizierung in der Bildung - Kritische Perspektiven auf digitale Vermessung in pädagogischen Kontexten (Mandy Schiefner, Sandra Hofhues, Andreas Breiter) (2023)
- All is data? - Ein (Schreib-)Gespräch unter Herausgeber:innen (Mandy Schiefner-Rohs, Sandra Hofhues, Andreas Breiter)
- Datafixation of education (Pekka Mertala)
- All is data? - Ein (Schreib-)Gespräch unter Herausgeber:innen (Mandy Schiefner-Rohs, Sandra Hofhues, Andreas Breiter)
- On the Limits of Artificial Intelligence (AI) in Education (Neil Selwyn) (2024)
- KI für Lehrkräfte - ein offenes Lehrbuch (Colin de la Higuera, Jotsna Iyer) (2024)
- Large Language Models und ihre Potenziale im Bildungssystem - Impulspapier der Ständigen Wissenschaftlichen Kommission der Kultusministerkonferenz (SWK Ständige Wissenschaftliche Kommission der KMK) (2024)
- Education for the Age of AI (Charles Fadel, Alexis Black, Robbie Taylor, Janet Slesinski, Katie Dunn) (2024)
- AI in education is a public problem (Ben Williamson) (2024)
- What’s in a Name? - Auditing Large Language Models for Race and Gender Bias (Amit Haim, Alejandro Salinas, Julian Nyarko) (2024)
- Dialect prejudice predicts AI decisions about people's character, employability, and criminality (Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, Sharese King) (2024)
- Alles überall auf einmal - Wie Künstliche Intelligenz unsere Welt verändert und was wir dabei gewinnen können (Miriam Meckel, Léa Steinacker) (2024)
- 7. Deepfakes und Desinformation: Das Ende der Wahrheit?
- 9. Das ethische Spiegelkabinett - Wenn KI Werte nachahmt
- 7. Deepfakes und Desinformation: Das Ende der Wahrheit?
- Challenging systematic prejudices - An Investigation into Bias Against Women and Girls in Large Language Models (UNESCO United Nations Educational, Scientific and Cultural Org.) (2024)
- Künstliche Intelligenz in der Schule - Chancen nutzen, Herausforderungen meistern (LCH Dachverband Schweizer Lehrerinnen und Lehrer) (2024)
- The impact of generative artificial intelligence on socioeconomic inequalities and policymaking (Valerio Capraro, Austin Lentsch, Daron Acemoglu, Selin Akgun, Aisel Akhmedova, Ennio Bilancini, Jean-François Bonnefon, Pablo Brañas-Garza, Luigi Butera, Karen Douglas, Jim Everett, Gerd Gigerenzer, Christine Greenhow, Daniel Hashimoto, Julianne Holt-Lunstad, Jolanda Jetten, Simon Johnson, Werner Kunz, Chiara Longoni, Pete Lunn, Simone Natale, Stefanie Paluch, Iyad Rahwan, Neil Selwyn, Vivek Singh, Siddharth Suri, Jennifer Sutcliffe, Joe Tomlinson, Sander van der Linden, Paul Van Lange, Friederike Wall, Jay Van Bavel, Riccardo Viale) (2024)
- Die digitale Kalaschnikow (Ursina Haller) (2024)
- Die wahren Kosten der Künstlichen Intelligenz (Christian R. Ulbrich, Urs Gasser) (2024)
- Nexus - Eine kurze Geschichte der Informationsnetzwerke von der Steinzeit bis zur künstlichen Intelligenz (Yuval Noah Harari) (2024)
- AI Snake Oil - What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference (Arvind Narayanan, Sayash Kapoor) (2024)
- Generative KI – jenseits von Euphorie und einfachen Lösungen (Judith Simon, Indra Spiecker gen. Döhmann, Ulrike von Luxburg) (2024)
- Handbuch Lernen mit digitalen Medien (3. Auflage) - Wege der Transformation (Gerold Brägger, Hans-Günter Rolff) (2025)
- 1. Generative Machine-Learning-Systeme - Die nächste Herausforderung des digitalen Leitmedienwechsels (Beat Döbeli Honegger) (2025)
- 1. Generative Machine-Learning-Systeme - Die nächste Herausforderung des digitalen Leitmedienwechsels (Beat Döbeli Honegger) (2025)
- Wissenschaftliches Schreiben mit KI (Isabella Buck) (2025)


 Biblionetz-History
Biblionetz-History {kind=link}
{kind=link}